In E-commerce, where seasonal peaks can exceed hundreds of thousands of orders per hour, load balancing is not a supporting feature—it is infrastructure oxygen.
As systems scale across regions, instances, and protocols, engineers must understand how L4 Load Balancing, L7 Load Balancing, and Consistent Hashing work together to keep traffic flowing predictably under pressure.
Understanding Load Balancing in Modern Architecture
Load balancing fundamentally means distributing incoming traffic across multiple backend servers so that no single machine becomes a bottleneck or a single point of failure.Behind a simple "Add to Cart" click, dozens of layered decisions determine which server receives the request and how subsequent requests from the same user are routed in a predictable, efficient manner.
Modern cloud infrastructures use a combination of L4 (Transport Layer), L7 (Application Layer), and Consistent Hashing strategies for different use cases. Each approach solves a different problem: efficient routing, intelligent routing, and stable routing under churn.
L4 Load Balancing – Fast, Lightweight, Fundamental
L4 Load Balancing works at the transport layer (TCP/UDP). It does not understand HTTP methods, cookies, headers, or payloads. It only looks at IP addresses and ports. This makes it extremely fast and capable of handling millions of concurrent connections with minimal overhead.L4 load balancers, such as AWS NLB, Google TCP LB, HAProxy (TCP mode), or NGINX stream mode, act as simple traffic directors. They maintain fairness in network connections, perform health checks, and distribute packets evenly using techniques like Round Robin and Least Connections.
Because they operate below the application layer, they are protocol-agnostic.
Example
When a user visits the homepage (E-commerce), the initial HTTPS connection is routed by an L4 balancer. It forwards TCP packets to one healthy application instance among many without caring whether the user is browsing products, adding to cart, or fetching recommendations. This makes L4 the foundation for frontend scalability.The strength of L4 is its speed. Its limitation is the lack of intelligence, as it cannot inspect requests to make routing decisions based on URLs, headers, or user attributes.
L7 Load Balancing – Smart, Context-Aware Routing
L7 Load Balancing works at the application layer (HTTP/HTTPS/WebSockets). It can inspect the full request—paths, headers, cookies, JWT tokens, MIME types—and make intelligent decisions. L7 load balancers or proxies such as AWS Application Load Balancer (ALB), NGINX, Envoy, Traefik, and Cloudflare understand intent.This enables powerful routing capabilities like:
- path-based routing (/products/* → Product Service),
- header-based routing (mobile vs desktop clients),
- canary deployments,
- A/B testing,
- protocol upgrades (WebSockets, gRPC),
- traffic shadowing,
- request rewriting and transformation.
A canary deployment is a risk-mitigation strategy for releasing new software versions by gradually rolling them out to a small subset of users (the "canary group") before a full release, allowing for real-world testing, performance monitoring, and quick rollback if issues arise, much like canaries in coal mines warned miners of gas.
A/B testing (or split testing) is a method to compare two versions (A & B) of something (like a webpage, email, or app feature) by showing them to different user groups to see which performs better at achieving a goal, like more clicks or sign-ups, using data to make informed decisions instead of guesses. It involves splitting traffic, running the experiment, collecting data, and using statistical analysis to find the "winner" for optimization.
Example
A single ALB may route:/products/123 to the Catalog Service,
/cart to the Cart Service,
/checkout to the Checkout Orchestrator,
/orders/history to the Order Service,
/recommendations to a Machine Learning API.
This routing intelligence enables microservice architectures to expose clean API surfaces without clients needing to know service boundaries.
L7 load balancing is essential for modern E-commerce because it allows you to scale components independently, experiment with new features safely, and apply sophisticated access-control and caching policies.
Consistent Hashing – Stable Routing with Minimal Disruption
Load balancing is not just about spreading load—sometimes it is about sticking requests to the same backend consistently. That is where Consistent Hashing shines.Consistent Hashing is a technique used to map requests or keys to servers in a way that minimizes disruption when nodes are added or removed. Unlike standard hashing (modulo-based), which remaps almost all keys when a node changes, consistent hashing only remaps a small fraction of them.
This property is essential when the system requires:
- session stickiness,
- cache affinity,
- shard routing,
- distributed storage mapping,
- real-time personalization.
Session stickiness: The load balancer keeps a user connected to the same backend server for the entire session, ensuring consistent experience and avoiding re-authentication or state loss.Systems like Redis Cluster, Cassandra, Kafka partitioners, and service meshes (Envoy/Istio) rely heavily on consistent hashing.
Cache affinity: Requests for the same data are routed to the server that already has that data cached, improving speed and reducing redundant computation.
Shard routing: Incoming requests are directed to a specific shard or partition based on a hashing rule, ensuring that related data is always handled by the correct backend segment.
Distributed storage mapping: Data is placed across multiple storage nodes using a consistent mapping strategy, allowing efficient lookup and high scalability without centralized coordination.
Real-time personalization: Requests are routed to systems that maintain user-specific context, enabling dynamic, personalized responses such as tailored recommendations or pricing.
Why typical load balancing fails for caches
If a cart service uses Redis caching and the load balancer spreads requests randomly, a user's cart might land in different Redis nodes during their session, constantly missing cache.To ensure a user's session or personalized recommendations route consistently, an E-commerce platform may hash based on:
user ID,
session ID,
cart ID,
device ID.
This ensures that the same user always reaches the same backend node or shard, preserving cache locality and reducing latency. When scaling horizontally—adding or removing service instances—consistent hashing ensures minimal churn and stable performance.
How Consistent Hashing Works (Explained Simply)
Traditional hashing uses something like:
serverIndex = hash(key) % numberOfServers
The problem is, if the number of servers changes (scale up/down), almost every key remaps, which destroys caching consistency.
Consistent Hashing solves this by placing both servers and keys on a ring. Clients route a key to the next server clockwise on the ring.
Step 1: Build a Hash Ring
1. Hash each server's ID (e.g., IP/hostname).
2. Place them on a circular ring ranging from 0 → 2^32.
3. Hash each request key (e.g., userId, cartId) and place it on the same ring.
When a key is hashed, it moves CLOCKWISE to the nearest server on the ring.
Step 2: Routing a Request
For example, a userId=42 hashes to a position on the ring.
If the next server clockwise is Server B, all requests for user 42 always go to Server B.
This keeps request–cache affinity stable.
Step 3: Node Failure Scenario
- Server B fails (goes offline)
- In modulo hashing → almost ALL keys remap.
- In consistent hashing → only keys that belonged to Server B are affected.
What happens?
All keys that mapped to Server B now move to the next server clockwise, say Server C.
All keys that belonged to Server A and Server C remain untouched.
Before Failure: A → B → C → A
After Failure: A → C → A
Only B's segment is redistributed. The rest of the ring is perfectly stable. This minimizes cache misses and preserves system performance.
Step 4: New Node Addition (Scale Out)
- Adding Server D to handle more load.
- Server D is placed on the ring based on its hash.
What happens?
Only keys in the segment between previous server and Server D move to Server D.
All other keys stay on their existing nodes.
Old Ring: A → B → C → A
New Ring: A → B → C → D → A
Only a portion of keys previously assigned to A (or C depending on position) now move to D.
Minimal key movement = minimal cache disruption.
Virtual Nodes (VNodes) – Improving Load Distribution
In real systems, servers don't have identical performance characteristics. If we use just one position per server on the ring:
- One server might accidentally get a large portion of the hash space.
- Load may be uneven (hotspots).
- Adding/removing nodes causes larger shifts in key ownership.
Virtual Nodes fix this by placing each server multiple times on the ring, making the distribution smoother and more predictable.
Ring WITHOUT Virtual Nodes (Uneven Load)
Let's say we have 3 servers: A, B, C. And based on their hashes, they land like this:------ A ---- B -------------------- C ---- (back to A)
You can see visually:
Segment A→B is small
Segment B→C is huge
Segment C→A is moderate
This means:
Server B gets very little traffic
Server C gets disproportionately more traffic
Load is uneven and unpredictable
Even a single node failure creates massive rebalancing.
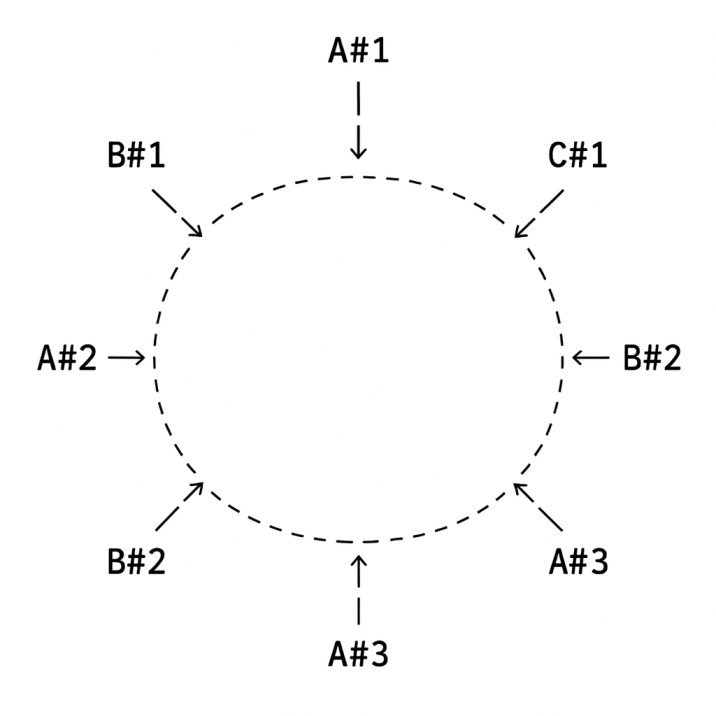
Ring WITH Virtual Nodes (Even Load)
Now let's place each server on the ring 3 times:A → A#1, A#2, A#3
B → B#1, B#2, B#3
C → C#1, C#2, C#3
Suppose their hashes land like this around the ring:
A#1 → C#1 → B#1 → A#2 → C#2 → B#2 → A#3 → C#3 → B#3 → (back to A#1)
Now the ring is much more interleaved. Each segment is now:
A#1 to C#1 → Server A
C#1 to B#1 → Server C
B#1 to A#2 → Server B
A#2 to C#2 → Server A
C#2 to B#2 → Server C
B#2 to A#3 → Server B
A#3 to C#3 → Server A
C#3 to B#3 → Server C
B#3 to A#1 → Server B
Resulting distribution:
Server A handles 3 segments
Server B handles 3 segments
Server C handles 3 segments
Because the server's load becomes the sum of multiple small segments:
- No server is stuck with one giant chunk
- Natural randomization spreads load evenly
- Key hot-spots get distributed across servers
- Large-scale variance is smoothed out
Even if A#1 lands next to C#1 in a poorly spaced region, A still has A#2 and A#3 distributed elsewhere.
Node Addition Without VNodes (Huge Disruption)
Adding Server D without VNodes:--- A --- B --------------------- C ---- (D added here)
If D's hash falls in the largest segment (C→A), it suddenly receives all keys from that range.
This causes:
- Big cache turnover
- Sudden change in load distribution
- "Hot" nodes instantly cooled or overloaded
Node Addition WITH VNodes (Minimal Disruption)
With virtual nodes (say D#1, D#2, D#3), the new placements are scattered:A#1 → C#1 → D#1 → B#1 → A#2 → C#2 → B#2 → D#2 → A#3 → C#3 → B#3 → D#3 → A#1
Only the small segments immediately before each D#k move to D.
Instead of: 40% keys moving → without VNodes
You get: ~11% moved → with VNodes
This is dramatically less expensive and far more predictable.
Conclusion
L4 Load Balancer receives raw TCP connections and distributes load quickly across edge servers. L4 Load Balancing gives raw speed and massive throughput.L7 Load Balancer inspects HTTP requests and routes to the appropriate microservice based on paths, headers, or version rules. L7 Load Balancing adds intelligence and control.
Consistent Hashing ensures that session-affinitized services (recommendations, caching, certain ML models, user-auth services) have stable routing to specific shards or pods. Consistent Hashing ensures stability and affinity under system churn.
Together, they form the backbone of high-scale E-commerce platforms, ensuring that every customer—from browsing to checkout—gets a fast, reliable, and personalized experience, even under extreme load.