Do we want the most accurate answer, or the fastest one? Do we continue operating during partial failure, or do we halt critical actions to preserve correctness?
Many engineering teams often misunderstand these trade-offs as being purely driven by system failures. However, even when a distributed system is working perfectly, there is still a fundamental choice to be made between latency and consistency.
This broader perspective is captured by the PACELC Theorem.
What is PACELC?
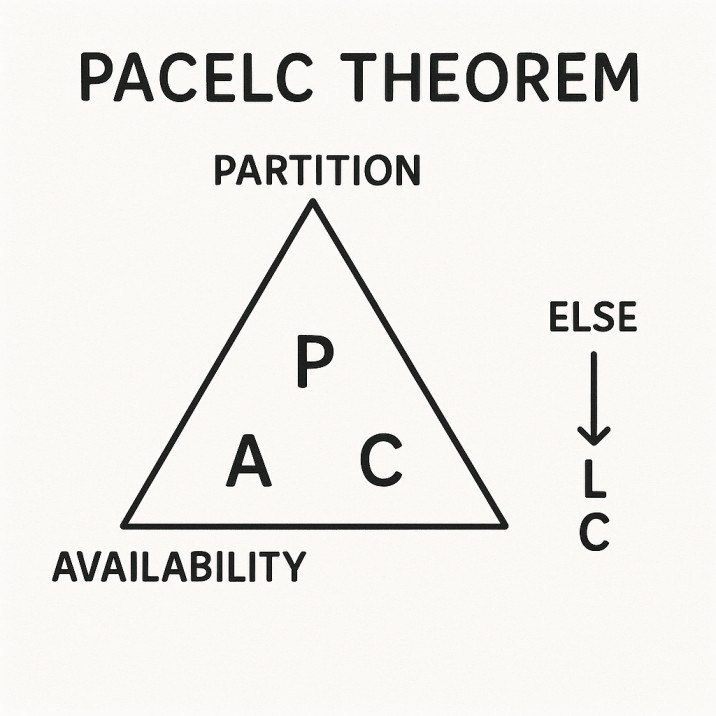
PACELC Theorem expands the CAP theorem by expressing what happens not only during network partitions (P) but also else (E) — when the system is working normally. In short:If a network Partition occurs (P), choose between Availability (A) and Consistency (C); Else (E), choose between Latency (L) and Consistency (C).
In simpler terms:
- During failure, you choose Availability or Consistency.
- During normal operation, you choose Latency or Consistency.
This means consistency comes at a cost both under failure and under perfect health. Even with no outages, we may be sacrificing performance to replicate data synchronously across regions.
Why PACELC Matters More Than CAP
- CAP describes what happens when systems fail.
- PACELC describes how systems behave all the time.
Modern E-commerce platforms operate across continents. Product catalog data is cached globally, inventory is updated in real time, and payments must synchronize across financial systems. With growing scale, most user interactions happen closer to the edge, where fast responses matter.
PACELC helps engineers decide when to return slightly stale data for speed and when to block until data is consistent.
Example: Product Search vs Inventory Checkout
Example 1: E-commerce Search (PA/EL Choice)
Searching items across categories must be extremely fast. Users browse repeatedly, often without buying. Systems like DynamoDB, Elasticsearch, Cassandra often choose high Availability during failure and prioritize low Latency during normal operation.In PACELC terms, they behave like:
PA / EL → Prioritize Availability during Partition, prioritize low Latency Else
So when you search for "running shoes," the system responds instantly, even if some data is slightly stale. Showing "200 items" instead of "198 items" doesn't hurt the business.
Example 2: Inventory Checkout (PC/EC Choice)
Inventory for checkout must be strictly accurate. Overselling 100 shoes when only 20 remain leads to cancellations, refund operations, customer loss, and logistical failures. The system must prioritize Consistency during partition and Consistency during normal operation, even if it slows some requests.In PACELC terms:
PC / EC → Prioritize Consistency during Partition; Else prioritize Consistency over Latency
This is why checkout might occasionally show: "Sorry, this item just went out of stock." The system chooses correctness over speed, even when everything is working normally.
Payment Example: PACELC in Action
When a user pays, the transaction must be recorded correctly across:- Payment gateway
- Order database
- Ledger service
- Fraud systems
Even a slight inconsistency can lead to double billing or lost payment proof. Systems like Spanner or strongly consistent PostgreSQL clusters often choose:
PC / EC
The write may take an extra 50–150 milliseconds to obtain quorum across regions. That latency cost is acceptable to avoid incorrect financial records. PACELC tells us that even when the network is healthy, we still pay the consistency penalty.
Summary
Even with no failures, we still choose between latency and consistency.This is the core idea PACELC adds to CAP. Distributed architecture isn't only designed for disaster. It's designed for everyday user experience. Fast catalog browsing, quick recommendations, and low-friction search need speed. Accurate checkout, unique coupon redemption, and secure payments need consistency.
PACELC reminds us that trade-offs are not temporary—they are permanent, and they must be aligned with business value.